PostgreSQL과 같은 데이터베이스에서 RabbitMQ와 같은 메시지 브로커가 필요한 이유는 무엇입니까?
Celery 와 같은 스케줄링 시스템을위한 작업 / 메시지 큐를 생성하는 데 사용할 수있는 RabbitMQ 와 같은 메시지 브로커 를 처음 사용합니다 .
자, 여기 질문이 있습니다 :
PostgreSQL 에서 새로운 작업을 추가하고 Celery와 같은 소비자 프로그램 에서 사용할 수있는 테이블을 만들 수 있습니다.
왜 지구상에서 RabbitMQ와 같은 완전히 새로운 기술을 설치하고 싶습니까?
PostgreSQL과 같은 데이터베이스가 분산 환경에서 작동 할 수 있기 때문에 스케일링이 답이 될 수 없다고 생각합니다.
데이터베이스가 특정 문제에 어떤 문제를 일으키는 지 봤습니다.
- 폴링은 데이터베이스 사용량이 적고 성능이 낮게 유지
- 테이블 잠금-> 다시 낮은 성능
- 수백만 행의 작업-> 다시 말하면 폴링 성능이 낮습니다.
이제 RabbitMQ 또는 이와 같은 다른 메시지 브로커는 이러한 문제를 어떻게 해결합니까?
또한 AMQP프로토콜이 다음과 같은 것으로 나타났습니다 . 그게 뭐에요?
Redis 를 메시지 브로커로도 사용할 수 있습니까 ? RabbitMQ보다 Memcached와 더 유사합니다.
이것에 약간의 빛을 비추십시오!
토끼의 대기열은 메모리에 상주하므로이를 데이터베이스에서 구현하는 것보다 훨씬 빠릅니다. (양호한) 전용 메시지 큐는 스로틀 링 / 흐름 제어와 같은 필수 큐잉 관련 기능과 서로 다른 라우팅 알고리즘을 선택하여 커플의 이름을 지정할 수있는 기능을 제공해야합니다 (토끼가 제공하는 것 이상). 프로젝트의 크기에 따라 메시지 전달 구성 요소를 데이터베이스와 분리하여 구성 할 수 있으므로 한 구성 요소에 많은로드가 발생하더라도 다른 구성 요소의 작업을 방해하지 않아도됩니다.
언급 한 문제에 관해서는 :
데이터베이스를 흐릿하고 낮은 성능으로 유지하는 폴링 : Rabbitmq를 사용하여 생산자는 폴링보다 훨씬 성능이 뛰어난 소비자에게 업데이트를 푸시 할 수 있습니다 . 데이터는 필요할 때 소비자에게 간단히 전송되므로 낭비되는 점검이 필요 없습니다.
테이블 잠금-> 다시 낮은 성능 : 잠글 테이블이 없습니다. : P
수백만 행의 작업-> 다시 폴링 성능이 낮습니다. 위에서 언급 한 것처럼 Rabbitmq는 RAM에 상주하므로 더 빠르게 작동하며 흐름 제어를 제공합니다. 필요한 경우 RAM이 부족한 경우 디스크를 사용하여 메시지를 임시로 저장할 수도 있습니다. 2.0 이후 Rabbit은 RAM 사용량이 크게 향상되었습니다. 클러스터링 옵션도 사용할 수 있습니다.
AMQP와 관련하여 정말 멋진 기능은 "교환"이며 다른 교환으로 라우팅하는 기능입니다. 따라서 유연성이 향상되고 확장시 매우 유용 할 수있는 다양한 정교한 라우팅 유형을 만들 수 있습니다. 좋은 예를 보려면 다음을 참조하십시오.

(출처 : springsource.com )
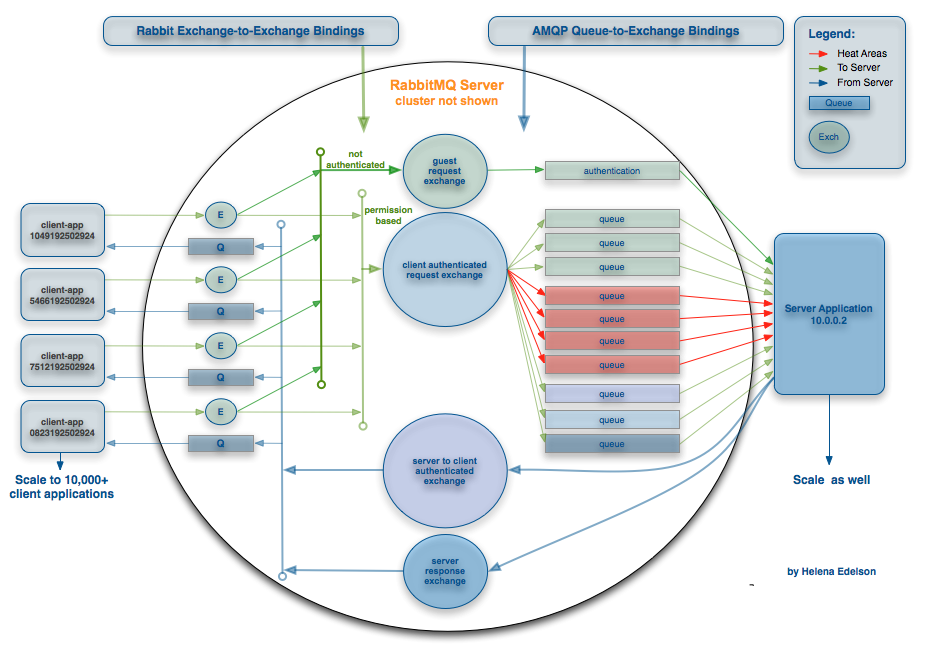{kind=link}
Finally, in regards to redis, yes, it can be used as a message broker, and can do well. However, Rabbitmq has more message queuing features than redis, as rabbitmq was built from the ground up to be a full-featured enterprise-level dedicated message queue. Redis on the other hand was primarily created to be an in-memory key-value store(though it does much more than that now; its even referred to as a swiss army knife). Still, I've read/heard many people achieving good results with Redis for smaller sized projects, but haven't heard much about it in larger applications.
Here is an example of redis being used in a long-polling chat implementation: http://eflorenzano.com/blog/2011/02/16/technology-behind-convore/
PostgreSQL 9.5
PostgreSQL 9.5 incorporates SELECT ... FOR UPDATE ... SKIP LOCKED. This makes implementing working queuing systems a lot simpler and easier. You may no longer require an external queueing system since it's now simple to fetch 'n' rows that no other session has locked, and keep them locked until you commit confirmation that the work is done. It even works with two-phase transactions for when external co-ordination is required.
External queueing systems remain useful, providing canned functionality, proven performance, integration with other systems, options for horizontal scaling and federation, etc. Nonetheless, for simple cases you don't really need them anymore.
Older versions
You don't need such tools, but using one may make life easier. Doing queueing in the database looks easy, but you'll discover in practice that high performance, reliable concurrent queuing is really hard to do right in a relational database.
That's why tools like PGQ exist.
You can get rid of polling in PostgreSQL by using LISTEN and NOTIFY, but that won't solve the problem of reliably handing out entries off the top of the queue to exactly one consumer while preserving highly concurrent operation and not blocking inserts. All the simple and obvious solutions you think will solve that problem actually don't in the real world, and tend to degenerate into less efficient versions of single-worker queue fetching.
If you don't need highly concurrent multi-worker queue fetches then using a single queue table in PostgreSQL is entirely reasonable.
'IT story' 카테고리의 다른 글
| 배열의 첫 번째 요소를 얻는 방법? (0) | 2020.05.12 |
|---|---|
| C ++ 표준은 iostream의 성능 저하를 요구합니까, 아니면 구현이 좋지 않은 경우에만 처리합니까? (0) | 2020.05.12 |
| Webpack을 사용하여 vue.js 프로젝트에서 at ( '@') 로그인 경로를 사용하여 ES6 가져 오기 (0) | 2020.05.12 |
| C ++ 11에서 로컬 정적 변수 초기화는 스레드로부터 안전합니까? (0) | 2020.05.12 |
| package-lock.json의 역할은 무엇입니까? (0) | 2020.05.12 |